
Open Culture Data: Opening GLAM Data Bottom-up
Lotte Belice Baltussen, The Netherlands, Johan Oomen, The Netherlands, Maarten Brinkerink, The Netherlands, Maarten Zeinstra, The Netherlands, Nikki Timmermans, The Netherlands
Abstract
Open Culture Data started as a grassroots movement at the end of 2011, with the aim to open up data in the cultural sector and stimulate (creative) reuse. In this context, we organised a hackathon, which resulted in the creation of 13 Open Culture Data apps. After this successful first half year, a solid network of cultural heritage professionals, copyright and open data experts and developers was formed. In April 2012, an Open Culture Data masterclass started in which 17 institutions got practical, technical and legal advice on how to open their data for re-use. Furthermore, we organised an app competition and three hackathons, in which developers were stimulated to re-use Open Cultural Datasets in new and innovative ways. These activities resulted in 27 more apps and 34 open datasets. In this paper we share lessons-learned that will inform heritage institutions with real-life quantitative and qualitative experiences, best practices and guidelines from their peers for opening up data and the ways in which this data is reused. Since the open culture data field is still relatively young, this is highly relevant information needed to stimulate others to join the open data movement. To this end, we are already taking steps to cross the borders and let Europe know about the initiative, on both a practical and a policy level.
Keywords: open data, open culture data, bottom-up, creative commons, GLAMwiki, community
1. Introduction
Open data is an increasingly popular form of publishing information on the Internet, as “new modes of discovery, collaboration, and knowledge creation [are gaining power]” (Edson, 2010). Open data is data that can be accessed, distributed, and reused by everyone, even for commercial purposes, without the need to explicitly ask the data owner for permission. Many (semi-)governmental organizations already openly publish parts of their data. Open data is also high on the digital agenda in Europe (Niggemann, De Decker, & Lévy, 2011; European Commission, 2006). Vice President for the Digital Agenda of the European Commission Neelie Kroes (2011) has even made the following call to action:
I urge cultural institutions to open up control of their data…there is a wonderful opportunity to show how cultural material can contribute to innovation, how it can become a driver of new developments. Museums, archives and libraries should not miss it. (p. 6)
The majority of GLAMs (galleries, libraries, archives, museums) have yet to implement this new form of transparency and public access in their policies. GLAMs do, however, increasingly realize that open access to data helps drive users to online content, for instance by providing content for reuse on Wikipedia articles. Hence, open data supports cultural institutions in the fulfilment of their public mission to open up access to our collective heritage, not just through their own channels, but outside as well. As Waibel and Erway (2009) state: “for [GLAM] content to be truly accessible, it needs to be where the users are, embedded in their daily networked lives.” It also stimulates collaboration in the GLAM world and beyond. This allows the creation of new services and supports creative reuse of material in new productions. As Bill Joy notes in “Joy’s law”: “No matter who you are, most of the smartest people work for someone else” (Lakhani & Panetta, 2007). Thus, encouraging external parties to reuse publicly available sources stimulates innovation in the GLAM sector and results in services of higher quality and diversity that contribute to the public mission of making collections broadly available.
Based on these developments, the Dutch Heritage Innovators Network (Grob et al., 2011) members Kennisland and the Netherlands Institute for Sound and Vision, together with Hack de Overheid (Hack the Government), launched the “Open Culture Data” (Open Cultuur Data in Dutch) initiative in September 2011. We are a network of cultural professionals, developers, designers, copyright specialists, and open data experts who aim to make cultural datasets available under open conditions and stimulate the creation of useful and innovative applications in which these datasets are incorporated. The initiative promotes dialogue and the sharing of experiences on how to get more cultural data openly available. In this context, we have organized a masterclass for cultural institutions, a series of hackathons, and an app competition.
In this paper, we share the lessons learned Open Culture Data’s successful first year and a half, with the aim of providing insights in how to establish an open data-minded cultural sector, based on our experiences in the Netherlands. We first provide a bird’s-eye view of the GLAM open data landscape, before we describe what Open Culture Data is, how it was set up, and the outcomes of the network’s activities: developing a network of interested institutions, educating them in how to open up their collections, and connecting with a community of developers. Finally, we reflect on the benefits and risks for GLAMs of being “open,” and on our future plans.
2. Open culture milestones – Overview
Although open data has not been adopted in the GLAM world on a large scale, important pioneers, movements, projects, and organizations are spearheading and fostering open data developments in the GLAM sector. The timeline in figure 1 serves as an (inevitably incomplete) overview of milestones from which Open Culture Data has learned and by which we have been inspired:
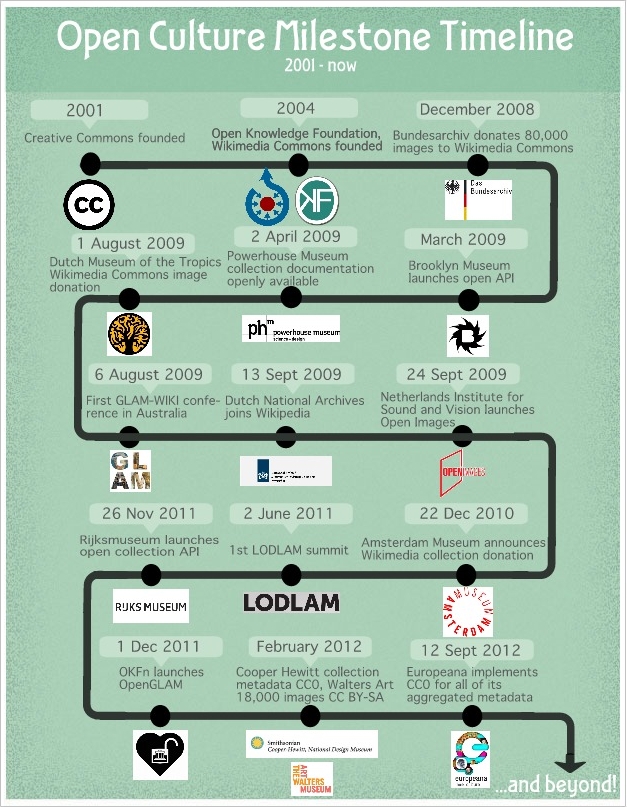
Figure 1: Open culture milestone timeline. Created by Lotte Belice Baltussen, (CC BY-SA http://creativecommons.org/licenses/by-sa/3.0)
A large and growing collection of case studies can be found on the Open Knowledge Foundation’s OpenGLAM (http://openglam.org/category/case-studies/) and the GLAM-WIKI website (http://www.glamwiki.org/).
3. What Is Open Culture Data?
Open Culture Data started in September 2011 by defining guidelines in order to make clear to contributors what principles they should at least adhere to:
- Open Culture Data is knowledge and information of cultural institutions, organizations, or initiatives about their collections and/or works
- Everyone can consult, use, spread, and reuse Open Culture Data (through an open license or by making material available in the public domain)
- Open Culture Data is available in a digital (standard) format that makes reuse possible
- The structure and possible applications of Open Culture Data are documented in a data blog
- The provider of the Open Culture Data is prepared to answer questions about the data from interested parties and respects the efforts that the open data community invests in developing new applications
Open Culture Data makes a clear distinction between content and metadata. All digitized cultural objects are defined as content (e.g., scanned paintings, photographed objects, and digital texts). All descriptive information about an object is called metadata (e.g., name of the creator, year of creation, size of the object, description). The accepted open licenses compliant with the rules above are:
- Metadata: Creative Commons Public Domain Dedication (CC0). By using CC0, you explicitly waive any rights there might be on your metadata, including European specific database rights. Database right is a specific European Union sui generis right, which protects databases “that reflect ‘substantial investment.’” (Hugenholtz, 2004)
- Content: Public Domain Mark if copyright has expired; Creative Commons Attribution (CC BY) or Creative Commons Attribution-ShareAlike (CC BY-SA) in cases where the organization has (cleared) the rights.

Figure 2: The licenses and rights demarcations accepted by Open Culture Data (image by Kennisland, CC BY-SA http://creativecommons.org/licenses/by-sa/3.0)
There are three reasons for opting to use these specific open licenses. First of all, Creative Commons licenses are ported and used worldwide. Furthermore, these choices are in line with rights requirements of other projects that support open data. Europeana has made CC0 for metadata a prerequisite for data providers who want to make their collection information available through this European cultural collections aggregator. In total, Europeana has aggregated over 20 million cultural objects (Europeana, 2012). In January 2013, the board of directors of the Digital Public Library of America (DPLA) also recommended following the CC0 policy for metadata. Thirdly, regarding content, CC BY and CC BY-SA are the only two licenses compliant with the open content rules of Wikimedia Commons, the media archive of Wikipedia. They consider the other four Creative Commons licenses to be too restrictive, because they do not permit commercial reuse and/or making derivative works (Wikimedia Commons, 2013).
4. Open Culture Data: From ad-hoc activity to a solid network
The First Four Months – The Emergence Of A Network
In September 2011, a small group of innovators from the Dutch Heritage Innovators Network, a network of cultural heritage professionals, and Hack de Overheid, a network of open data activists who have been active in the Netherlands since 2009, saw an opportunity to promote open data in the cultural sector and joined forces. We started the Open Culture Data network (http://www.opencultuurdata.nl) by participating in a national Apps for the Netherlands competition (http://nationaleappprijs.nl), which was primarily aimed at reusing open governmental data. Within three months, the network identified, described, and contributed eight open datasets from six individual data providers to the competition: ab-c media, Amsterdam Museum, Dutch National Archives, EYE Film Institute Netherlands, Netherlands Institute for Sound and Vision, and Rijksmuseum.
Representatives from these organizations pitched their datasets at a big hackathon organized by Hack de Overheid (500 developers) in November, and as a result thirteen apps were made with data available through the Open Culture Data network. Eight developers submitted their apps for the competition. Surprisingly for an app competition aimed at reuse of governmental data, three of the apps made with culture data won prizes in the competition, including the overall winner. Glimworm IT won the contest with its app, Vistory (an app to recreate historical footage scenes with your smartphone camera; see figure 3). The app Rijksmonumenten.info (a mashup of data about monumental heritage in the Netherlands), made by Arjan den Boer, won the Education category; and the encouragement prize went to ConnectedCollection (a cross-collection search widget), made by Wout van Wezel (Cit). (see Annex I and Annex II for an overview of all datasets and apps)

Figure 3: Apps for the Netherlands winner Vistory (http://www.vistory.nl/)
Although Open Culture Data started out as ad hoc and experimental, it was clear that there was a need for culture data that could be openly reused and a strong network to position and promote culture in the (inter)national open data arena. Due to this need, combined with the enthusiasm of the developers, we concluded that we should continue and expand the Open Culture Data activities.
Structuring The Ad-Hoc Experience
In early 2012, the initiative was adopted by the digitization project Images for the Future (http://imagesforthefuture.com), and Creative Commons Netherlands (http://creativecommons.nl). In March 2012, the network received moral support from the open community when it received the European Public Sector Information Platform Trailblazer award (http://epsiplatform.eu/content/winners-epsi-trailblazers-2012) as an initiative that has done something new and exciting with open data in Europe. At the same time, a common set of questions on how to open up kept emerging from professionals from various types of cultural institutions. Therefore, we decided to develop two activities that would connect data owners, app developers, and policy makers, in order for them to mutually inspire and help each other.
First, Creative Commons Netherlands organized a masterclass that started in April 2012. In this masterclass, representatives of various GLAM organizations took part in order to assist them with courseware and lectures that would guide them through the process of opening up a cultural dataset. Secondly, and parallel to these efforts, an app competition was set up, with the aim to stimulate developers to creatively reuse the open culture datasets. The outcomes of these two activities are described in the following paragraphs.
5. Results and lessons learned from 1.5 years of Open Culture Data
The Masterclass: A Fast Track To Opening Up
The Open Culture Data masterclass started in April 2012 and ended in June 2012. We hoped to attract ten to fifteen applications, but a grand total of twenty-four Dutch cultural institutions signed up, of which seventeen took part in the end. The seven that did not eventually join the masterclass either had collections of which the rights status was so unclear that we advised against them taking part at that point in time, or backed out due to time constraints.
Representatives from the institutions who already opened up data in 2011 acted as coaches in the masterclass. Various types of organizations—large and (very) small—signed up: five archives (regional and national), one library, six museums, four knowledge institutes, one sector institute, and one Dutch tourism project. The participants had various levels of knowledge about open data, ranging from people whose organizations already had open data working groups to those whose management was not yet fully convinced of the benefits of opening up. The masterclass touched upon the following topics which guided them through the process necessary to open datasets:
- Building blocks of copyright
- Technology and tools (from open licensing to APIs)
- Reuse and applications
- Benefits and risks
- Hackathons
As part of the course material for this masterclass, three (openly licensed) white papers were written about legal and technological issues and useful tools to publish collections and metadata (Zeinstra & Timmermans, 2012a, b, and c). Each participant was assigned an experienced open data coach to aid them with questions or issues that would arise. Most importantly, coaches helped with the finer details of copyright law and the rights status of digitized works, since rights issues were the most hard to grasp for the participants. As a result, a large part of the coaching in the masterclass was directed at these questions.
The (Perceived) Risks Of Open Data
After guest lectures by copyright experts, data experts, and app developers in the first three masterclasses, the knowledge and experience acquired up to that point by the participants was applied in a workshop. In this workshop held in mid-May 2012, the (perceived) benefits and risks for cultural institutions of opening up were discussed by the seventeen masterclass participants in three breakout sessions. The basis for the discussion was Europeana’s white paper on open data: “The Problem of the Yellow Milkmaid” (Verwayen et al., 2011). In this paper, the top ten benefits and risks of open data are summarized based on an expert workshop with cultural institutions. It should be noted that the paper focuses exclusively on opening metadata, and does not deal with open content, which is more problematic, since the rights of metadata often lie with cultural institutions themselves in contrast to the rights of the content itself. For instance, of the more than 23 million records in Europeana from cultural heritage organizations all over Europe, the rights status is as follows:
- Rights reserved (9,199,423 total)
- Rights reserved – Free access: 7,042,439
- Rights reserved – Restricted access: 961,939
- Rights reserved – Paid access: 1,195,045
- Public Domain (4,544,653 total)
- Public Domain Mark: 3,782,261
- CC0 (Public Domain Dedication): 762,392
- Creative Commons license (1,802,538 total)
- Creative Commons – Attribution: 47,836
- Creative Commons – Attribution-ShareAlike: 1,001,399
- Creative Commons – Attribution-NonCommercial: 156,595
- Creative Commons – Attribution-No Derivatives: 9,516
- Creative Commons – Attribution-NonCommercial–ShareAlike: 212,954
- Creative Commons – Attribution-NonCommercial–NoDerivatives: 374,238 (Europeana, 2013)
The numbers do not add up to 23 million, because some records do not have a clear rights statement. Still, the overview above demonstrates that in Europeana, most of the content has a “rights reserved” statement. This does not per se mean that the data providers do not own the rights to this content (they might choose to not offer it openly), but it is a great indication that many collections still fall under copyright. Moreover, the collections made available through Europeana that do still fall under copyright are probably relatively easy to clear online access rights for; the content with a difficult rights status is probably not going to be online for quite a while.
Although the Europeana report has been written with a sole focus on metadata, the outcomes apply to open content benefits and risks as well, as we will demonstrate below. The top ten risks defined in the Europeana report are:

Figure 4: Risks of open data (image by JAM/Europeana. CC BY http://creativecommons.org/licenses/by/3.0)
A workshop with the same structure as the “Risks and Benefits” masterclass was held as part of the one-day symposium “Boss of your own metadata,” organized by the knowledge center Digital Heritage Netherlands (http://www.den.nl) on June 28, 2012. The workshop was held together with the Open Knowledge Foundation and was split into two parallel sessions attended by 40 people in total. Each parallel session consisted of a plenary introduction to the subject, after which the workshop attendees split over three groups. Again, the question was posed to first list the top three risks perceived by them or their organization, based on the Europeana report. These mirrored the top five list compiled by their Open Culture Masterclass peers, except for the order, which was slightly different:
| Open Culture Data Masterclass | “Boss of your own metadata” workshop |
| 1. Loss of attribution | 1. Loss of attribution |
| 2. Loss of control | 2. Loss of potential income |
| 3. Loss of potential income | 3. Loss of control |
| 4. Loss of brand value | 4. Privacy |
| 5. Privacy | 5. Loss of brand value |
Table 1: Top five risks of open data according to representatives of two groups of Dutch cultural organizations.
Based on this sample of almost sixty representatives of a variety of large and small cultural organizations in the Netherlands, we received insight in the main perceived risks of opening up metadata and content. The number one concern is that opening up collections will result in material being spread and reused without any credit going to the provider itself. This is related to the second point on the list: loss of control. If you cannot keep track of who uses your materials and how, organizations fear they no longer have control over their collections. The workshop participants did not fear a direct loss of income by making data openly available, but did foresee this could happen in the future, since third parties have the opportunity to develop new business models based on their datasets. The loss of brand value is related to both loss of attribution and control: if people don’t know the original source of a dataset, then the brand value of a GLAM organization that provided it does not become stronger. Finally, privacy issues are at stake for those GLAM organizations that have data containing personal information (e.g., genealogy data). This means that this issue might be more relevant for specific collections or organizations that have a lot of data on individuals.
The (Perceived) Benefits Of Open Data
The masterclass candidates and the attendees of the “Boss of your own metadata” workshop were also asked to repeat the exercise to list the top three benefits of open data they or their organization rank the highest.

Figure 5: Benefits of open data (image by JAM/Europeana. CC BY http://creativecommons.org/licenses/by/3.0)
The outcomes were again ranked in order of importance according to the two groups of workshop participants and differed slightly more than the perceived risks:
| Open Culture Data Masterclass | “Boss of your own metadata” workshop |
| 1. Public mission | 1. Public mission |
| 2. Data enrichment | 2. Data enrichment |
| 3. Increasing channels to end users | 3. Discoverability |
| 4. Increasing relevance | 4. Increasing channels to end users |
| 5. New customers | 5. Increasing relevance |
Table 2: Top five benefits of open data according to representatives of two groups of Dutch cultural organizations.
Overall, the consensus was that open data should be part of one’s public mission, especially if an organization received public funding. Making collections accessible to as many people as possible is simply at the heart of the vast majority of cultural heritage organizations, and this is reflected in the outcomes above. Furthermore, people indicated that by opening up, they expect to be able to enrich data through aggregators like Europeana or other parties, and consequently reingest this back into their own systems or websites. Also, enrichment for the participants meant being able to link their open data to that of other, related collections. Increasing the amount of channels (e.g., Wikipedia) through which end users can be reached is also an important perceived benefit of open data. This ties in with discoverability, which drives users to the provider’s website as a direct result of the open data being available in more channels. Increased relevance means that by opening up, (information about) collections can be used where online users are, such as social networks. The benefit of possibly attracting and interacting with new customers was only mentioned by some the masterclass participants.
Creative Reuse: Open Culture Data App Competition
In order to create interest in the open culture datasets and stimulate reuse, we launched our own app competition that ran from June 16 to December 31, 2012. We set out three main challenges for the developer community:
- Create applications that expand audience reach (online, offline, on site)
- Create applications in which the audience is reached in novel ways
- Create applications that connect different datasets
Instead of the short running time of a few weeks or even just a day we saw in many other competitions, we opted to give developers more time to come up with something interesting that actually worked, not just a mockup. There were four awards (gold, silver, bronze, Dutch National Archives prize) and a total prize pool of €7,500. The overall gold winner could win €3,000.
The competition was kicked off at a large hackathon event organized by Hack de Overheid in June 2012, in which Open Culture Data gave its own presentations and workshops. The masterclass participants that were ready (eight in total) and other open culture data providers pitched their data to a group of developers. Another similar, large-scale hackathon event was held in October 2012, and a smaller one specifically aimed at reuse of the data in games right before the December 31 deadline. Furthermore, many presentations to raise awareness of the competition and Open Culture Data itself were held between June and December, for instance at a developers conference, the Wikimedia Netherlands conference, and Communication and Media Design students.
In total, twenty-seven apps were submitted for the competition, a lot more than we had bargained for, and the quality of the apps also exceeded our expectations. A jury of five (two GLAM and two open data professionals, and one developer) picked the winners. First prize went to Muse app made by Femke van der Ster, Peter Henkes, and Jelle van der Ster (figure 6). Muse app allows you to create your own work of art with cutouts from world-famous old masters: sceneries, people, animals, objects, and skies. You can bring the cutouts to your own canvas, pinch, move, duplicate them to make a collage, and share your masterpiece through Facebook, e-mail, put it on your camera-roll, or put it in an online Web gallery where it can be reviewed by art critics and other Muse-app creators.

Figure 6: Gold-prize winner Muse app, developed by Femke van der Ster, Jelle van der Ster, and Peter Henkes (http://www.museapp.org/).
The silver went to Histagram by Frontwise (Richard Jong), an app where you can make digital postcards based on historical pictures (figure 7).

Figure 7: Silver-prize winner Histagram, developed by Richard Jong (http://www.frontwise.nl/lab/histagram).
Third prize went to SimMuseum by Hay Kranen, a Web game in which you can play a museum director, collect work of arts, and build your own museum (figure 8).

Figure 8: Bronze-prize winner SimMuseum, developed by Hay Kranen (http://simmuseum.haykranen.nl/).
The Dutch National Archives prize went to Tijdbalk.nl, made by Arjan den Boer (figure 9). Users can make their own timeline with historical photos photos and add their own content as well.

Figure 9: National Archives-prize winner Tijdbalk.nl, developed by Arjan den Boer (http://tijdbalk.nl/).
By organizing an app competition, Open Culture Data was able to raise awareness and set the agenda for open data with, and broaden the perspectives for, cultural heritage institutions of what can happen when you open up; however, some important lessons were learned:
- It doesn’t just happen: It will always take time and resources to get the results that we did. During the competition period, we continuously raised awareness in the developer community and asked them what they wanted and needed, and we were always available for questions and input.
- Sustainability: More needs to be done to make sure that app competitions result in something sustainable. Developers, data providers, and networks like Open Culture Data need to join forces and make sure that they understand one another so that supply and demand are more aligned to each other. We have seen in both the national and international open data movement that a majority of apps developed within competitions will disappear, because they cannot be sustained in the long run and often remain in the prototype stage. Before you have a real killer app, a lot of other and similar apps will come along first. This is why Open Culture Data will focus on the development of sustainable business models with possible revenue streams for both the developers and the cultural institutions in the future.
- Not all data is equally popular: Fourteen of the thirty-four available datasets were actually used. The Rijksmuseum dataset, with its well-known collection, 125,000 high-resolution images, and easy-to-use API, was the most popular and used in nine out of twenty-seven apps submitted for the competition. In general, collections that offer both metadata and content were more popular than open datasets that only contained metadata. When metadata-only data was used, this was usually done in combination with other datasets that did have images or videos. One exception was the Arts Holland set that contains up-to-date information about cultural events in the Netherlands.
6. Future Perspectives
Open Culture Data also looks towards the future. Now that many cultural datasets from early adopters in the Dutch cultural heritage sector can be reused, a need arises to measure the effects of opening up culture. Although measuring online success is gaining ground in the GLAM sector, specific tools for measuring the effects of opening up data are far and few between (Finnis et al., 2011). At several sessions of our master class, during workshops organized by us at the various hackathons, and at the ‘Boss of your own metadata’ symposium, various stakeholders (representatives from GLAMs, policy makers, and developers) expressed the need for a measurement model for the impact of opening up culture. The lack of evidence-based arguments in favor of opening up culture even became a central theme for an expert meeting with GLAM professionals at the Open Knowledge Festival in Helsinki that we co-organized.
Since the open culture data field is still relatively young, this highly relevant information is still often in an anecdotal stage. To improve this situation and to contribute to the accumulation of data about the impact of opening up cultural data and content, Open Culture Data will develop a measurement model (GLAMetrics) to gather evidence about the effects of open distribution. A first version of this model is currently being tested within the Open Culture Data network. Based on our experiences with testing the measurement model, we will produce a survey that we can circulate widely among GLAMs that are openly distributing their data and/or content. Since we aren’t yet aware of any other international initiatives aiming to measure the impact of open culture, we are planning to collaborate with international networks like Europeana, OpenGLAM, and the GLAM-WIKI project. This will allow us to circulate our survey based on our measurement model on an international level, both to get more substantial and representative datasets to analyze and to contribute to the maturing of the open culture data movement on a larger scale than just the Netherlands. We also hope to organize workshops during relevant conference and gatherings to assist GLAMs in completing our survey and contributing their impact data. The results of our impact analysis will be widely disseminated through presentations and in an electronic publication/paper (that will of course be made openly and freely available online).
The results of our open culture impact analysis are not the only outcome from the Open Culture Data activities in the Netherlands that we hope to share with the international open culture data movement. For the P2PU (http://p2pu.org) grassroots open education project, we are developing free online courses for GLAM professionals who are interested in opening up their data or content, based on our master class. And within the EU-funded Apps4EU project (http://ec.europa.eu/information_society/apps/projects/factsheet/index.cfm?project_ref=325090), we are translating some of our resources for reuse by similar initiatives starting up in other European countries. The first actual European Open Culture Data spinoff was launched in Belgium September 2012 and will organize its first hackathon in the spring of 2013. Another spinoff in Finland is also in the works (Pekel, 2012).
7. Conclusion
When Open Culture Data kicked off at the end of 2011, we started with eight datasets from six different providers. After the masterclass held between April and June 2012, ten out of the seventeen participants had made additional datasets openly available through Open Culture Data. Others that had not taken part in the masterclass have either been approached by us or contacted us themselves in order to open up even more data. In total, there are now thirty-four Open Culture Datasets of twenty-two individual providers available under open licenses, altogether containing over 29 million records, that contain rich metadata and content (1.6 million images, texts, sounds, videos). A diverse range of forty apps has been made based on Open Culture Datasets.
The most important pitfall we have experienced in the ability of cultural institutions to open up—besides the risks discussed in this paper—is the lack of copyright knowledge in the sector, and the lack of (up-to-date) information about the copyright status of collections. The cultural institutions that have contributed datasets have experienced that the added value of doing so lies primarily with their public mission and their aims to make their collections available and meaningful to the public. Furthermore, by opening up datasets, they are making themselves more findable and relevant online, since their data can be shared and accessed on multiple locations, such as Wikipedia. Also, the apps that have been made so far have provided novel insights into how open culture data can be reused, enriched, and connected in ways the institutions themselves could not have imagined. We have determined the following lessons learned that we feel are critical for our success, and for that of similar initiatives:
- Innovators lead the way. By gathering the right group of professionals in the cultural domain who believed in the (potential) power of open and were willing to experiment, we created a small but very powerful vanguard. For example: When the prestigious Dutch Rijksmuseum joined the initiative, this inspired other institutions like the National Museum of Antiquities to also participate.
- Create practical examples. The fact that cultural institutions are hesitant to join the open data movement has a lot to do with either a lack of knowledge or a fear of the consequences for their current way of operating: fear that their business model might be endangered and fear of people abusing their data, or reusing it for purposes they don’t agree with, like misrepresenting the data. These fears are not per se grounded in fact and experience (see for instance Verwayen et al., 2011), and it withholds institutions from what they can gain by opening up, like experimenting with innovative concepts for new services or applications. We have learned that by putting open culture data in practice and actively stimulating the reuse of the data, cultural institutions can be convinced to join the movement.
- Thinking about open culture data requires a multidisciplinary perspective. Many cultural institutions have particular ideas about new applications and services for their data, but this is only one way of looking at it. We have learned that connecting cultural institutions with the “outside world”—the world of hackers, designers, and students, but also other data providers and commercial companies—is not only a lot of fun, but is also very helpful to institutions in finding new ways to make arts and culture meaningful in the digital era.
With these key issues, risks, and success factors in mind, combined with the knowledge Open Culture Data and related initiatives have readily available, we believe that institutions of all sizes and with small and large budgets alike can join the open movement. In the coming years, we hope to see a vast increase of freely sharable and reusable collections that inspires an ever-growing, connected GLAM community.
Acknowledgements
Open Culture Data and its app competition were made possible with the support of the digitization programme Images for the Future. Thanks to Creative Commons Netherlands for developing the masterclass. A special thanks goes out to to Tim de Haan (Dutch National Archives) and Yannick H’Madoun (Kennisland) for their input and support. We’re much obliged to the OpenGLAM branch of the Open Knowledge Foundation—Sam Leon and Joris Pekel in particular—for co-organizing workshops with us and being available for advice and feedback. Of course, we are very much indebted to the pioneers in the culture sector who see the benefits of opening up and have provided their datasets freely for reuse by anyone. Finally, we are extremely grateful to all developers who have spent their valuable free time building apps based on these open datasets, and have shown us that smart people indeed mostly work for someone else.
References
Edson, M. (2010). Museums and the Commons: Helping makers get stuff done. Slideshare. Last updated December 16, 2010. Consulted January 24, 2013. http://www.slideshare.net/edsonm/museums-and-the-commons-helping-makers-get-stuff-done-6779050
European Commission. (2006). “Public Sector information – Raw data for new services and products.” Europe’s Information Society Thematic Portal. Last updated December 2012. Consulted January 5, 2013. http://ec.europa.eu/information_society/policy/psi/index_en.htm
Europeana. (2012). “Europeana’s huge cultural dataset opens for re-use.” Published September 12, 2012. Consulted Consulted January 24, 2013. http://pro.europeana.eu/web/guest/press-release?p_p_id=itemdetailsportlet_WAR_europeanaportlet_INSTANCE_FX4c&p_p_lifecycle=1&p_p_state=normal&p_p_mode=view&p_p_col_id=column-2&p_p_col_count=1&_itemdetailsportlet_WAR_europeanaportlet_INSTANCE_FX4c_itemId=1284453&_itemdetailsportlet_WAR_europeanaportlet_INSTANCE_FX4c_javax.portlet.action=setItemId
Europeana API (2013). Query of the Europeana API on the rights status of all records in the Europeana database. Consulted January 2013. http://pro.europeana.eu/api
Finnis, J., S. Chan, & R. Clements. (2011). “How to evaluate online success? A new piece of action research.” In J. Trant & D. Bearman (Eds.). Museums and the Web 2011: Proceedings. Toronto: Archives & Museum Informatics. Published March 31, 2011. Consulted October 23, 2012. http://conference.archimuse.com/mw2011/papers/how_to_evaluate_online_success
Grob, B., L. B. Baltussen, L. Heijmans, R. Kits, P. Lemmens, E. Schreurs, N. Timmermans, & E. van Tuijn. (2011). “Why reinvent the wheel over and over again? How an offline platform stimulates online innovation.” In J. Trant & D. Bearman (Eds.). Museums and the Web 2011: Proceedings. Toronto: Archives & Museum Informatics. Published March 31, 2011. Consulted January 24, 2013. http://conference.archimuse.com/mw2011/papers/why_reinvent_the_wheel
Hugenholtz, P. B. (2004). “Abuse of database right. Sole-source information banks under the EU Database Directive.” In F. Lévêque & H. Shelanski (Eds.). Antitrust, Patents and Copyright: EU and US Perspectives. Presented at the Antitrust, Patent and Copyright, Cheltenham: Edward Elgar Pub. 203–219. Consulted January 20, 2013. http://www.ivir.nl/publications/hugenholtz/abuseofdatabaseright.html
Kroes, N. (2011). “Foreword: Culture and Open Data: How Can Museums Get the Best from their Digital Assets?” Uncommon Culture: From Closed Doors to Open Gates, vol. 2, no. 1/2. Consulted December 10, 2012. http://www.firstmonday.org/htbin/cgiwrap/bin/ojs/index.php/UC/article/view/3771/3053
Niggemann, E., J. De Decker, & M. Lévy. (2011). The new renaissance. Reflection group on bringing Europeʼs cultural heritage online. Brussels: European Commission. http://ec.europa.eu/information_society/activities/digital_libraries/doc/refgroup/final_report_cds.pdf
Pekel. J. (2012). OpenGLAM workshop at the OKFestival. OpenGLAM blog. Published September 27, 2012. Consulted February 28, 2013. http://openglam.org/2012/09/27/openglam-workshop-at-the-okfestival-2/
Verwayen, H., M. Arnoldus, & P. B. Kaufman. (2011). “The problem of the yellow milkmaid. A business model perspective on open metadata.” Den Haag: Europeana. Consulted December 10, 2012. http://version1.europeana.eu/web/europeana-project/whitepapers/
Waibel, G., & R. Erway. (2009). “Think global, act local–library, archive and museum collaboration.” Museum Management and Curatorship 24(4), 1–14.
Wikimedia Commons. (2013). “Commons:Licensing.” Wikipedia, The Free Encyclopedia. Published January 14, 2013. Consulted January 21, 2013. http://commons.wikimedia.org/wiki/Licensing
Zeinstra, M., & N. Timmermans. (2012a). Auteursrecht en Open Data in de Culturele Sector. Amsterdam: Creative Commons Nederland. Consulted. http://www.opencultuurdata.nl/wp-content/uploads/2012/07/Auteursrecht-en-Open-Data-in-de-Culturele-Sector.pdf
Zeinstra, M., & N. Timmermans. (2012b). Creative Commons-licenties en methoden voor het openstellen van culturele data. Amsterdam: Creative Commons Nederland. Consulted. http://www.opencultuurdata.nl/wp-content/uploads/2012/07/Creative-Commons-licenties-en-methoden-voor-het-openstellen-van-culturele-data.pdf
Zeinstra, M., & N. Timmermans. (2012c). Open data: delen, verbinden, verrijken. Amsterdam: Creative Commons Nederland. Consulted. http://www.opencultuurdata.nl/wp-content/uploads/2012/07/Open-Data-Delen-Verbinden-en-Verrijken.pdf
Annex I. Datasets overview (alphabetical order)
| Institute | Type of data | Records/ objects | Linked Open Data star ranking | License scheme |
| Amsterdam Museum | Collection data | 70,000 images | API, XML, OAI/PMH, LOD***** | Images PD, metadata under CC0 |
| Arts Holland | Events data | 100,000 events (1,400 locations, 45 genres) | API**** | Metadata under CC0 |
| Archief Eemland | Collection data | 2,000 maps | Open Search API**** | Images under CC-BY, metadata under CC0 |
| Centraal Museum | Collection data | 8,500 fashion records (650 images) | XML dump** | Images PD/ CC0, metadata under CC0 |
| Europeana | Collection metadata | 23,000,000 records | API ***** |
Metadata under CC0 |
| EYE Film Institute Netherlands | Collection metadata | 170 records on Dutch film | ODS file*** | Metadata under CC0 |
| Fries Museum | Collection data | 17,000 fashion records (2,100 images) | XML file** | Images PD, metadata under CC0 |
| Groene Hart Archieven | Collection data | 80 old maps | Txt and CSV file** | Images PD, metadata under CC0 |
| Koninklijke Bibliotheek | Collection data | 454,800 political transcripts 11,240 books |
API, XML, Full text OCR**** | Political transcripts fully CC0 Book content in PD, book metadata under CC0 |
| Nationaal Archief (Dutch National Archives) | Collection data | 141,177 press photos 477 old maps 2,873 WOI photos 693 polder maps |
Open search API, OAI-PMH**** | Images CC BY-SA Maps CC0, metadata under CC0 WOI photos: PD mark Polder maps: CC0 |
| National Committee for 4 and 5 May | Collection metadata | 3,500 war monuments | XML-feed and dump, OAI*** | Metadata under CC0 |
| Netherlands Institute for Sound and Vision | Collection data | 2,100 sounds12,000 images 18,000 Wiki articles1,800 videos |
SoundCloud API, MediaWiki API***** | Sounds under CC BY-SAImages and articles under CC BY-SAVideos under CC BY-SA |
| NIOD Institute for War, Holocaust and Genocide Studies | Collection metadata | 140,000 metadata records | OAI-PMH**** | Metadata under CC0 |
| Regionaal Archief Leiden | Collection data | 4,086,171 genealogy records 80,000 image records (and some images) |
OpenSearch API, OAI-PMH harvesting**** | Genealogy records: images under CC BY-SA, metadata CC0 Images records: images under CC BY-SA, metadata CC0 |
| Regionaal Archief Nijmegen | Collection data | 684 images of WOII soldiers | Flickr API**** | Images under CC BY-SA |
| Rijksdienst voor het Cultureel Erfgoed | Collection data | 550,000 images 150,000 library records |
API, OAI-PMH**** | Images under CC BY-SA, metadata under CC0 |
| Rijksmonumenten | Collection data (enriched) | 61,000 monuments, enriched with context sources like Wikipedia | API**** | Images CC BY-SA, |
| Rijksmuseum | Collection data | 111,000 images | API, OAI-PMH**** | Images in PD, metadata under CC0 |
| Rijksmuseum van Oudheden (Dutch National Museum of Antiquities) | Collection data | 150,000 images | API, OAI-PMH**** | Images under CC-BY, metadata under CC0 |
| Tropenmuseum (Dutch Museum of the Tropics) | Collection data | 50,000 images | Wikimedia Commons API**** | Images under CC BY-SA |
| University Library Utrecht |
Collection data | 111 old maps | OAI-PMH**** | Images in PD, metadata under CC0 |
| Visserijmuseum Zoutkamp | Collection data | 562 records | API, XML**** | Images under CC BY, metadata under CC0 |
| Total: 22 data providers |
Total: 29,223,938Images: 1,153,407 Videos: 1,800 Audio: 2,100 Texts: 484,040 Metadata records without content: 27.582.591 |
Annex II. Reuse overview (alphabetical order)
| App | Made by | Dataset used |
| Anefo 1959-1989 | Michiel Doeven | National Archives |
| ANEFOetbal | Jeroen Hoefnagels, Daan Marcellis | National Archives |
| Arkyves ICONCLASS Browser | Etienne Posthumus (Arkyves) | Rijksmuseum |
| Art from the Rijksmuseum | Maarten Trompper | Rijksmuseum |
| Bites | Stijn van Vilsteren, Tom Toepol, Jente Insing, Robbert van der Steenhoven | Sound and Vision |
| Cabaretier Archief | Tom Merkestijn, Derk Schermacher, Dennis Pol | National Archives, Sound and Vision |
| Connected Collection | Wout van Wezel (Cit) | Amsterdam Museum, National Archives, Rijksmuseum, Sound and Vision |
| CultHunt | Ruben Kroes, Joep Voorn, Steve Zonneveld, Sander Smeekes | Amsterdam Museum |
| Doek voor in je Hoek | Hoppinger (Andra Veraart, Arno Hartensveld, Cies Breijs, Maarten van den Hoek, Rolf van de Krol, Wouter Ramaker) | Rijksmuseum |
| Dutch Film Angle | Ernst Dommershuijzen | EYE Film Institute Netherlands, National Archives |
| Gezichten van het Rijksmuseum | Hans van den Berg en Arjan den Boer | Rijksmuseum |
| Het Virtuele Rijksmuseum | Hay Kranen | Rijksmuseum |
| Heatmaps Monumenten | Arjan den Boer | Rijksmonumenten, University Library Utrecht |
| Histagram | Frontwise (Richard Jong) | National Archives |
| Historische kaarten op de iPad | Kars Alfrink, Chris Eidhof | National Archives |
| Maak Jezelf Rijk(s) | Fabian van Zwam, Thierry van Remortel, Mehdi Ebadi, Michael Tukker | Rijksmuseum |
| Map the War | Dennis Adriaansen | NIOD |
| Mix van Nederland | Linsey Jepma, Paul Vonk, Burhan Eskin, Samira Abdelwajid en Mellissa Geutskens | Sound and Vision |
| Muse App | Femke van der Ster, Peter Henkes, Jelle van der Ster | Amsterdam Museum, Rijksmuseum |
| Muse – The Personal Mobile Museum | Glimworm IT (Jonathan Carter, Paul Manwaring & Deniz Tezcan) | Rijksmuseum, Wikipedia |
| Naar Toen | Willem van der Ham, Arthur Meyer, Mobzili | National Archives, RCE, Rijksmonumenten, Rijksmuseum |
| Open Beelden verrijkt | Jaap Blom (Sound and Vision) | Amsterdam Museum, Rijksmuseum, Sound and Vision |
| Openarchief Twitterstreams | Hans Nouwens | Amsterdam Museum, Rijksmuseum |
| OpenDataNederland.org | Bas van Dijk, Marthijn van den Heuvel | All |
| Randomapp | Nick Visser, Mike van Rossum, Joshua Nijman, Marc Apon | Arts Holland |
| Rijksmonumenten | Terry Elk (Elk ICT Services) | RCE, Wikipedia |
| Rijksmonumenten.info | Hans van der Berg en Arjan den Boer (ab-c media) | Flickr, RCE, Wikimedia, Wikipedia |
| Rijksmuseum | Tizio BV (Pascal de Vink, Gerald Vruggink, Remco Dazelaar) | Rijksmuseum |
| Rijksmuseum Meesterwerken | Henk Jurriens | Rijksmuseum |
| Rijksmuseum Tijdlijn | Ronald Klip | Rijksmuseum |
| Rijksmuseum Quiz | Nico Witteman | Rijksmuseum |
| Rijks-Quiz | Ronald Klip | Rijksmuseum |
| SimMuseum | Hay Kranen | Amsterdam Museum, Flickr, Freesound.org, Jamendo, National Archives, Rijksmuseum, Rijksoverheid.nl, Sound and Vision, Visserijmuseum Zoutkamp, Wikimedia Commons |
| Sounds Visual | Sander Veenhof | Sound and Vision |
| Tijdbalk.nl | Arjan den Boer | National Archives, Sound and Vision |
| Tom’s Tijdmachine | Geert Beskers, Joris Bijsterveld, Luc Waardenburg, Bram Blom, Jeffrey Beckers | Sound and Vision |
| Tube’s List | Jonathan Henderson | Arts Holland, Tubelight |
| WeAmsterdam | Rowdy Boon, Shaun Oostveen, Trisha van Engelen, Bas Kranendonk | Arts Holland |
| Where on Earth Is… | Jeroen Tietema, Mattijs Hoitink, Yoram Meijaard | Amsterdam Museum, Wikipedia |
| Vistory | Glimworm IT (Jonathan Carter, Paul Manwaring & Deniz Tezcan) | Sound and Vision |
| Total: 40 apps |
Cite as:
L. Baltussen, J. Oomen, M. Brinkerink, M. Zeinstra and N. Timmermans, Open Culture Data: Opening GLAM Data Bottom-up. In Museums and the Web 2013, N. Proctor & R. Cherry (eds). Silver Spring, MD: Museums and the Web. Published January 31, 2013. Consulted .
https://mw2013.museumsandtheweb.com/paper/open-culture-data-opening-glam-data-bottom-up/